Det har vært litt snakk om svenske matematiske bommer og denslags, men det som ikke har vært så mye kommentert er at den epidemiologiske modellen folkene på Imperial College brukte og som var tungt med i vurderingen for hva UK skulle gjøre angivelig er et massivt clusterfuck av elendig kode og proppfull av feil (det er visstnok ikke mulig å replikere resultatene fra kjøring til kjøring med identiske datasett og en hel del andre ting). Koden er sluppet på GitHub, det er ikke koden som ble kjørt, men resultatet av at folk hos Microsoft har bruke en måneds tid på å rese opp, dele opp og gjøre det hele mildt lesbart for utenforstående. Opprinnelig var det en enkelt fil på 15.000 kodelinjer. Imperial Collega nekter visstnok å slippe den opprinnelige koden av en eller annen grunn.
De som har sett på koden har ikke spesielt mye pent å si om den. Uavhengig av hva man skulle, burde, kunne gjort og hva som er riktig er det smått bekymringsverdig at det er slikt offentlig politikk kan baseres på. Det er fine titler og masse ekspertise bak men modellen de har laget er full av feil.
Om man ser bort fra at dette er en side for folk som tydeligvis ikke er så glade i lockdowns så er det en liten gjennomgang her fra en fyr som har satt seg inn i koden. Om man aldri har programmert er det neppe så interessant, men jeg fant det lesverdig.
by Sue Denim [Please note: a follow-up analysis is now […]

lockdownsceptics.org
I’ll illustrate with a few bugs. In issue 116 a UK “red team” at Edinburgh University reports that they tried to use a mode that stores data tables in a more efficient format for faster loading, and discovered – to their surprise – that the resulting predictions varied by around 80,000 deaths after 80 days:
That mode doesn’t change anything about the world being simulated, so this was obviously a bug.
The Imperial team’s response is that it doesn’t matter: they are “aware of some small non-determinisms”, but “this has historically been considered acceptable because of the general stochastic nature of the model”. Note the phrasing here: Imperial know their code has such bugs, but act as if it’s some inherent randomness of the universe, rather than a result of amateur coding. Apparently, in epidemiology, a difference of 80,000 deaths is “a small non-determinism”.
FHIs coronamodell er for øvrig, som vi var innom for ørten sider, tilgjengelig på GitHub og hvemsomhelst kan ta en titt om man vil. Koden er, om man skal være diplotmatisk, mindre pen, men den er samtidig såpass begrenset at det nok er mulig å ha oversikten over.
De eneste som skriver så godt som feilfri kode i verden er for øvrig NASA. Det krever veldig mye arbeid, omfattende rutiner og er veldig dyrt, men samtidig er det vanskelig å debugge en rakett eller noe annet om har forlatt jordens graviatasjonsfelt, så da er det fort billigst å gjøre det riktig på første forsøk.
edit: for motsatt syn, se f.eks her (essensen er at vitenskapelig kode er slik i sin natur, den er kun ment for de som har laget den og som har detaljert kjennskap til hva som skjer, ikke for å være ett eller annet komersielt programvareprodukt som kan slippes på markedet og vedlikeholdes av utenforstående.)
tl;dr: Many scientists write code that is crappy stylistically, but which is nevertheless scientifically correct (following rigorous checking/validation of outputs etc). Professional commercial sof…

philbull.wordpress.com

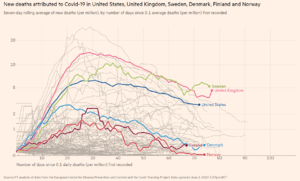






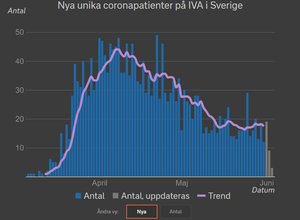


") Jeg har det ikke bare for å ha nevnt det....
Jeg har det ikke bare for å ha nevnt det....










