Det er mulig at dette er veldig gunstig for AI. Men uansett så bruker leger svært mye tid på slikt arbeid. I tillegg til rapportskriving er det etterhvert som sykehusene har kvittet seg med lavtlønte sekretærer, utallige timer som gå med til forskjellige registeroppføringer i datasystemer som ikke snakker sammen. Dersom man får en AI til å fungere her, vil det frigjøre enormt med resurser og enten gjøre helsetjenesten mer effektiv, eller billigere. Ref det som opprinnelig ble postet om at man fortsatt ikke kunne se noen økonomisk impact av AI. Jeg er overbevist om at dette etterhvert vil vise seg.
Jeg sammenliknet tidligere AI med kalkulatoren. Den er et veldig nyttig verktøy for å løse regnestykker, men den har aldri og vil aldri eliminere behovet for menneskelige bidrag i matematikken. Fordi matematikk til syvende og sist er av og for mennesker. Og tekst, programmeringskode, bilder og video er ikke noe annerledes i så måte. Alt er former for menneskelig syntaks.
En ny, systematisk kunnskapsoversikt ser nærmere på forskning om bruk av Chat GPT i høyere utdanning. Utdanningssektoren må tenke nytt, mener forskerne, to av dem fra KSU, som mener universiteter og høgskoler må veilede studenter i å bruke dette verktøyet på en transparent og etisk måte.
Faktisk er det enda litt verre. I artikkelen skriver de at ChatGPT «poses threats by positioning students as mere receivers of prepackaged knowledge». Det er ingenting prepackaged her, det er pretrained. Det er en vesentlig forskjell.
Packaging er det man gjør med en bok eller en artikkel: angir en kontekst og ruller ut et argument eller forklaring ut fra det. ChatGPT har ingen mulighet til å gjøre det.
Til spørsmålet i linken: Nei, ikke så lenge det er basert på hype langt forbi hva teknologien er i stand til å levere. Det må bli fantasidrevet boble etterfulgt av desillusjonert krasj. Vi er vel på tiende repeat av AI-historien nå, sånn ca.
Språkmodeller som GPT-4 er gode til å skrive, men har en stor og viktig svakhet: Resonnering. For å løse problemet lanserte OpenAI torsdag kveld en helt ny motor i ChatGPT. Den har fått navnet OpenAI o1.
– Jeg er litt lamslått, sier KI-professor Morten Goodwin. Han ga den nye modellen en eksamensoppgave på masternivå i faget nevrale nettverk (kunstig intelligens). Goodwin har selv undervist i faget i mange år.
Hmmm, mon tro hvor mye energi som går med per spørsmål til den?
Tydeligvis en iterativ prosess med et sekundært «adversial» nettverk som kritiserer og rangerer løsningsforslagene fra det primære nettverket. Det blir fort ti-gangeren i energiforbruk, minst, helt avhengig av hvor mange iterasjoner og hvor mange alternativer som skal genereres og rangeres i hver iterasjon. Brute force.
Nei, apropos det: Det ble lansert en ny billedgenererende AI nå i august. Den heter Flux.1 fra Black Forest Labs i Tyskland og er en variant av Stable Diffusion. Som tidligere versjoner av Stable Diffusion kan den lastes ned og kjøres lokalt. Den kan også settes opp til å lære lokalt på samme måte som tidligere modeller.
Training FLUX LoRAs has been challenging for users with limited VRAM resources. The process typically requires significant computational power, with existing solutions often demanding a minimum of 24GB VRAM, making it inaccessible for many users who wish to train their models locally. This...
www.marktechpost.com
Så jeg lastet den ned, fikk den til å kjøre på mitt etterhvert litt gamle Nvidia 1080Ti grafikkort, og matet den med de samme ~20 bildene fra familiealbumet for å lære den å lage bilder av meg. Den lærte mye fortere enn tidligere modeller og konvergerte til noe som ligner ganske mye på ca 1/10 av tiden. Det viktigste var at den konvergerte, og ikke begynte å generere dårligere bilder igjen bortenfor et visst punkt. Den bruker ca 10 min på å generere et bilde i f eks 900x1200 pixels oppløsning, ca 0,03 kWh energi. Læreprosessen var mer enn god nok etter et døgn, ca 3,6 kWh energiforbruk. Relativt billig moro.
Deretter kunne jeg be den generere bilder, f eks av en Porsche 981 Boxster:
Ikke så verst, det. Rett merke og modell, nokså troverdig gjengitt. Kanskje mer en 982 enn 981, men nær nok.
Jeg kunne også be den generere bilder av meg med bart og fedora-hatt, bare for å skremme fruen med.
Hun syntes ikke det var en god idé. Deretter kunne jeg be den generere bilder av meg i en 981 Boxster.
Tja, tjo, kanskje. Det fremsto kanskje som en bedre idé for fruen.
Men AI'en forstår fortsatt ingen verdens ting av hva den forsøker å vise.
Nei, vi blir ikke erstattet med det første, med mindre vi har jobb som illustratør uten spesielt høye krav til presisjon.
Surrealisme er den derimot bra på. Fruens squash ble ganske store i år, så hvorfor ikke?
Hun har nedlagt veto mot at jeg lærer den å lage bilder av henne. Jeg kan ikke forstå hvorfor.
Blir litt overrasket over at du mener disse resultatene skulle tilsi at vi ikke blir erstattet. Dette er vel utrolig bra? (Bortsett fra den åpenbare misforståelsen med bilen). Hvordan ser dette ut om 5 år?
Jeg ser at jeg kan bruke det, eksempelvis til å lage konseptuelle illustrasjoner og (nyttigst hittil) når jeg kommer inn i et møte som har pågått en stund og kan be copilot i Teams om å oppsummere hva som har skjedd så langt uten å måtte forstyrre de andre i møtet med dumme spørsmål. Det blir ikke presist, og den er ikke spesielt god på å gjengi norske navn, men godt nok til at jeg forstår hva som skjer. Det vil nok bli enda bedre om noen år.
Derimot ser jeg også at generativ AI helt grunnleggende ikke har noen modell av hvordan verden fungerer. Det betyr at man ikke kan stole på at det den genererer er riktig. Det kan være nær riktig, eller totalt j...a feil. Det er ingen ting i utviklingen som tilsier at det endres. Den er og blir en bullshit-generator, selv om man hiver på enda mer regnekraft og enda større underliggende datasett. Det vil også begrense hva den kan brukes til. Det må kompletteres av en menneskelig "sanity check" eller kuratering for å velge ut de beste alternativene i et billedsett. Derfor kanskje en nyttig ressurs, men ikke en erstatning for tenkende mennesker.
Det er jo et poeng at AI aldri vil kjenne til den virkelige verden av opplagte grunner. Jeg tror allikevel du undervurderer den framtidige betydningen av stadig mer regnekraften og utvikling av systemet. Jeg tror at man overvurderer den menneskelige faktor en i mye arbeid som gjøres nedover i organisasjoner. Bla kahnemans forsking (som er langt før noen visste om AI) viser at beslutninger generelt blir bedre av å følge algoritmer enn å bruke "expert opinions". Det er all grunn til å tro at man vil se en rivende utvikling og bedring av alle AIer de neste årene. Det er vel bare to år siden dette i det hele tatt ble en brukbar teknologi.
Jeg ser at jeg kan bruke det, eksempelvis til å lage konseptuelle illustrasjoner og (nyttigst hittil) når jeg kommer inn i et møte som har pågått en stund og kan be copilot i Teams om å oppsummere hva som har skjedd så langt uten å måtte forstyrre de andre i møtet med dumme spørsmål. Det blir ikke presist, og den er ikke spesielt god på å gjengi norske navn, men godt nok til at jeg forstår hva som skjer. Det vil nok bli enda bedre om noen år.
Vi har begynt å slå av copilot på teamsmøter. Har fått klager fra ledere som har lest disse "referatene" copilot er blotta for alt som heter humor, ironi, sarkasme etc. Det gikk alvorlig utover kvaliteten på møtene.
Epost er annen greie som har blitt krise med ai generert søppel, hvis jeg også da bruker ai for oppsummering, kulepunkter whatever så ender vi bare opp en schizofren copilot samtale.
Scenariet hvor jeg har nytte av det er mest "war room" ved driftsforstyrrelser. En slik sak vil typisk håndteres av et team i India til å begynne med, som så kaller inn andre ressurser både i India og Skandinavia ved behov. Noe det første de gjør når saken åpnes er å starte et Teams-møte for å håndtere den. De slår rutinemessig på transkripsjon og opptak fra start i tillegg til manuell loggføring. Jeg får automatisk mail når en slik sak kommer inn som berører mitt ansvarsområde, og jeg blir alltid invitert som "optional" i møtet for å håndtere den. Det går ca 10-20 minutter fra saken kommer inn til møtet er startet. Det kan skje når som helst på døgnet, f eks kl 07:31 sist søndag.
Teamet vil forsøke å gjøre en første analyse og sette i gang ressurser som kan feilsøke og rette problemet. Jeg bruker å gi dem en halvtime eller så, men om det ikke er løst til da vil jeg ofte gå inn i møtet for å forstå hva som skjer. Da er det også sendt SMS med varsling til diverse interessenter, inkludert berørte kunder, min sjef og hennes sjef igjen, og det vil ganske fort komme spørsmål tilbake til meg.
Da forventer jeg ikke at teamet skal droppe alt de holder på med for å briefe meg. Det har de ikke tid til. Heller spørre co-piloten om en oppsummering av saken så langt og lytte inn noen minutter på hva som foregår før jeg eventuelt stiller kontrollspørsmål og tilbyr hjelp.
Det er jo et poeng at AI aldri vil kjenne til den virkelige verden av opplagte grunner. Jeg tror allikevel du undervurderer den framtidige betydningen av stadig mer regnekraften og utvikling av systemet. Jeg tror at man overvurderer den menneskelige faktor en i mye arbeid som gjøres nedover i organisasjoner. Bla kahnemans forsking (som er langt før noen visste om AI) viser at beslutninger generelt blir bedre av å følge algoritmer enn å bruke "expert opinions". Det er all grunn til å tro at man vil se en rivende utvikling og bedring av alle AIer de neste årene. Det er vel bare to år siden dette i det hele tatt ble en brukbar teknologi.
Ser det poenget. Skrivepoolen av damer med skrivemaskiner som produserte rapporter fra håndskrevne notater og alle de grafiske assistentene som omformet kråketær på rutepapir til Powerpoints er allerede borte forlengst. Sekretærene som booket møter og reiser også. Dette kommer ikke til å reversere den utviklingen, akkurat. Jeg vet ikke hvor de er nå. Influencers på Instagram, kanskje?
Det er også noe interessant i å sammenligne hvordan AI'en fungerer med hvordan man selv fungerer. Jeg vil sjelden eller aldri tenke ferdig en hel setning før jeg begynner å snakke eller skrive. Det starter med en idé som skal formidles. Jeg begynner i en ende og forsøker å fullføre en meningsbærende setning, ofte med store og små korreksjoner underveis for å få det hele noenlunde grammatikalsk og overensstemmende med idéen jeg forsøkte å uttrykke.
Tilsvarende med hvordan man henter frem et visuelt minne. Det er ikke lagret fotografisk i alle sine detaljer, men mer som et slags konsept med noen hovedelementer. Hvis man forsøker å trekke det frem vil hjernen ofte fylle inn de manglende detaljene, muligens med noe helt annet enn hvordan det egentlig var, men som bevarer det helhetlige konseptet uten altfor mange selvmotsigelser.
Eksempel: Jeg forsøkte å beskrive for Flux hvordan jeg husket kryddermarkedet i Samarkand i 1988. Dette var "minnet" den fremkalte:
Når jeg kikker i fotoalbumet var det jo ikke slik, men det kunne kanskje ha vært omtrent slik.
Det må kompletteres av en menneskelig "sanity check" eller kuratering for å velge ut de beste alternativene i et billedsett. Derfor kanskje en nyttig ressurs, men ikke en erstatning for tenkende mennesker.
Dette minner meg om nokre eksperiment der eg har prøvt å få Dall-E (sikkert utdatert) til generera nokre generiske illustrasjonar til meg. Svært imponerande førsteforsøk, men ei endelaus rekkje frustrasjonar då eg prøvde å instruera om små spesifikke endringar.
Hadde du (der) bede om å få ein Poirot-mustasje kunne det fort enda opp med bowler og morning coat (altså, pre-1914-mote) også.
Eg har lurt litt på om vegen framover kan vera å laga AI-ar som ikkje genererer tekst eller ei scene uttrykt som pixelgrafikk, men meir komplekse dataformat, altså at verkelegheita vert definert ved at ein trenar opp AI-en i å produsera output til strukturerte element som allereie inneheld ein del grunnleggjande kunnskap (i form av strukturen i dataformatet) om kva som er fornuftig og ikkje.
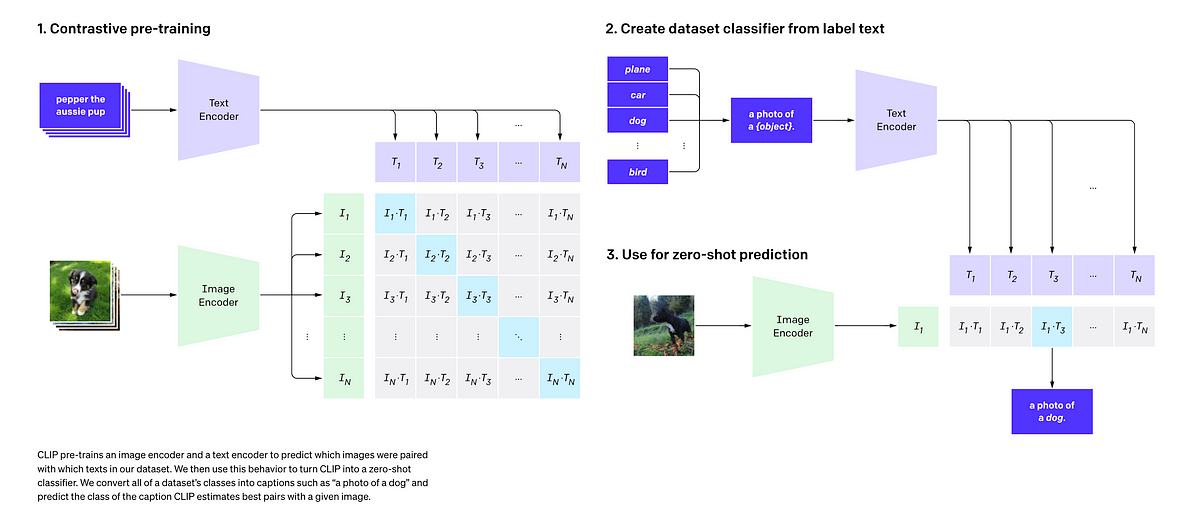
Mulig, men det er (så vidt jeg vet) ikke oppfunnet ennå. Dagens billedgenererende AI (diffusjonsmodeller) er en «mash-up» av tre hovedkomponenter. Først en mapping av både bilde og beskrivende tekst til punkter i et multidimensjonalt rom. Det gjør at en tekst uten bilde (eller med et bilde som bare er tilfeldig støy) blir mappet til punkter i nærheten av kombinert tekst og bilde i det rommet.
Deretter mater man dette inn i et nettverk som opprinnelig var ment for å fjerne støy fra røntgenbilder og lignende. Der reduseres bildet først til langt lavere oppløsning før det gradvis ekspanderes igjen mens «støyen» filtreres vekk i flere steg. Kombinasjonen av tekst og støy blir til tekst og bilde som anses å høre sammen i det multidimensjonale rommet.
Det gjør også at bilder av Poirots mustasje kommer nær bilder med tidsriktig antrekk og gatebilde. På det første bildet av meg spesifiserte jeg «glorious mustache», fedora-hatt, kamelhårsfrakk og et «timeless cityscape». Den fant på Empire State Building, det strenge ansiktsuttrykket og slipset med half Windsor knute selv, fordi det passet sammen med resten - nært i det multidimensjonale rommet den opererer i. Derimot går jeg ofte i blåstripede Swedemount skjorter kjøpt på Sportshopen i Grebbestad, så den assosierte tydeligvis slike med meg på begge bilder. Samme skjorte i to helt ulike situasjoner, sikkert også på flere av bildene i opplæringssettet.
Til slutt går det gjennom et nettverk som legger til mer detaljer og genererer det ferdige bildet i høyere oppløsning. Hele greia opererer på pixels i ulike oppløsninger, med representasjoner og transformasjoner i tensorform, og med komponenter som opprinnelig var ment for andre formål.
The meteoric rise of Diffusion Models is one of the biggest developments in Machine Learning in the past several years. Learn everything you need to know about Diffusion Models in this easy-to-follow guide.
A tweak to diffusion models, which are responsible for most of the recent excitement about AI-generated images, enables them to produce more realistic...
Stable Diffusion is an image generation tool that can be used to create detailed images. VAE is a technique used to improve the quality of images generated.
builtin.com
.
Det er nok mulig å lage et AI-nettverk som opererer på andre, mer strukturerte datarepresentasjoner, men jeg mistenker at det vil bli nokså domenespesifikke greier. Det vil formodentlig behøve komponenter som kanskje ikke finnes ennå. Opplæringen vil også forutsette et stort datasett av nettopp den strukturerte representasjonen med beskrivende tekst. Det er noe annet enn å bare la modellen inhalere alskens tekst og bilder fra internett, petabyte etter petabyte. Det er ikke helt opplagt for meg hvordan man skulle få til noe slikt annet enn for snevre og ekstremt betalingsvillige segmenter.
Det er all grunn til å tro at man vil se en rivende utvikling og bedring av alle AIer de neste årene. Det er vel bare to år siden dette i det hele tatt ble en brukbar teknologi.
En refleksjon til: Husk at jeg først snuste på deler av denne teknologien ca 1995. Den gangen kunne man såvidt lære opp et neuralt nettverk til å spille backgammon, ved i prinsippet å sette to kopier av nettverket til å spille mot hverandre og så oppdatere vektene ut fra hvem som vant. Jeg funderte på å gjøre det samme med hnefatafl, men det hadde kun akademisk interesse og knapt nok det. Så jeg gjorde noe annet, men har holdt litt øye med teknologien i de 30 årene som har gått. Multi layer networks, mønstergjenkjenning, billedprosessering, etc.
Husk også at et neuralt nettverk i prinsippet er en regresjonsmodell. Et trivielt neuralt nettverk med ett neuron vil gjøre en lineær regresjon og dra en rett linje y = a x + b gjennom et todimensjonalt datasett av oppgitte punkter (x, y), og vil formodentlig bruke minste kvadraters metode for å optimere verdiene av a og b til å passe best mulig med datasettet.
De av dere som først så dette komme tilsynelatende fra klar himmel ca 2023 har kanskje en annen ekstrapolering av hvor fort det går enn de av oss som mer tenker at dette fagfeltet omsider har fått til noen fengende partytriks etter 30-40 år langsom utvikling.
Produktivitetseffekten er vel snarere negativ, siden man både må bruke tid på å be forskjellige copilot-drevne dialogbokser om å gå vekk slik at man får jobbet (som gamle Clippy med ADHD, omtrent) og det dukket opp et utall nye muligheter til å kaste bort tid på fjas.
Og så snart kidsa har fått seg jobber i «prompt engineering» kommer en gammel rev i fedora og bytter ut CLIP-modellen i AI-en deres, slik at alle omhyggelig engineerede prompts plutselig gjør noe annet enn de trodde… bwahahaha!
Man kan sikkert poste dette her. Forskerne ble nok mektig overrasket både over at det de holdt på med tydeligvis anses som fysikk, og deretter over å få Nobel-prisen i fysikk for arbeidet. Velfortjent, uansett.
Paper’et ble publisert så sent som 2021. Det er eksepsjonelt at noen får en Nobelpris etter bare tre år.
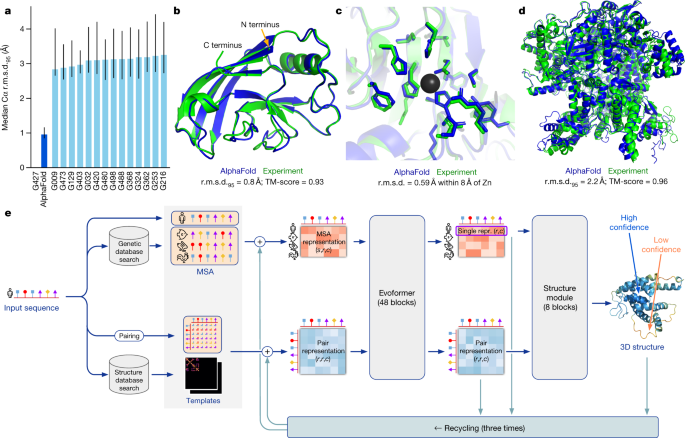
Dette er vel også et eksempel på generativ AI innenfor et såpass avgrenset område at det er mulig å bygge inn en del kunnskap om strukturene innenfor det området.
AlphaFold predicts protein structures with an accuracy competitive with experimental structures in the majority of cases using a novel deep learning architecture.
Vi har lett for å bli blendet slik at vi glemmer å investere i de kjedelige fremskrittene hvis sum gjør livene våre stadig bedre. Vi trenger ikke pie-in-the-sky-KI, men heller et stort forskningsprogram for grunnleggende IT-løsninger.
Brukte et stillbilde en venn sendte meg der han satt ved siden av en yngre kvinne i baksetet på en taxi. Instruerte Hailuo.ai til å generere et 6 sekunders videoklipp der hun kysser ham, mens bilen settes i bevegelse, ditto for bussen ved siden av dem, det hele foran Bussterminalen i Oslo. Det tok noen minutter og resultatet ble utrolig - et troverdig og pasjonert kyss mellom begge, nydelig lysspill fra solen gjennom vinduet, i hår, på tøyet, bilen i bevegelse, det samme for bussen, men kjøretøyene med ulik fart.
Deler ikke av hensyn til min venn, som kan risikere skilsmisse om hans kone skulle se videoen.
Jeg sammenliknet tidligere AI med kalkulatoren. Den er et veldig nyttig verktøy for å løse regnestykker, men den har aldri og vil aldri eliminere behovet for menneskelige bidrag i matematikken. Fordi matematikk til syvende og sist er av og for mennesker. Og tekst, programmeringskode, bilder og video er ikke noe annerledes i så måte. Alt er former for menneskelig syntaks.



















")