
Audio Science Review vokser seg større og får mer makt i spørsmålet om lyd. ASR er i stor grad et enmannsshow, ledet av Amir. Han måler elektronikk og lager lister som rangeres etter nøkkeltall som SINAD. Og han har begynt å anmelde høyttalere. Spørsmålet her er hvordan hans anmeldelser av høyttalere tåler en kritisk gjennomgang. Amir hevder han har en overlegen hørsel og følger ikke det han kaller «gullstandarden i lydforskning» - nemlig blindtesting - i sine anmeldelser. Derfor er det interessant å sammenlikne de subjektive anmeldelsene hans mot objektive data fra nærfeltmålinger som brukes som input i Harmans preferansealgoritme. Med andre ord er dette en anmeldelse av en anmelder basert på objektive data.
Teksten er på engelsk og ble nettopp publisert på Gearspace (https://gearspace.com/board/showpost.php?p=15445069&postcount=117).
Synes du teksten er lang, hopp ned til «conclusion».
- - - - - - - - - - - - - - - - - - - - -
EMPEROR’S NEW CLOTHES
Much has been said here about Amir and Audio Science Review. Because science is supposedly a self-correcting community of experts who constantly check each other’s work, I think it’s time to post a review of Amir’s speaker reviews. Amir bans critical people from his own site so I will post my review here (he just recently banned a user, GoldenOne, for making a critical review of MQA: https://www.audiosciencereview.com/...i-published-music-on-tidal-to-test-mqa.22549/).
To provide some background I think it’s interesting that Amir has ridiculed members of this forum many times, even here on Gearspace. In a discussion on MQA – the lossy, compressed audio format of Bob Stuart’s MQA Ltd. – he ridicules Brian Lucey’s hearing.
“I am not worried about what Bob has created. I am worried about technical mumbo jumbo and improper listening test results proffered as a serious attempt to counter the work of MQA. As I have said, before you guys go after the likes of Bob Stuart, you need to hire someone who can spell signal processing and psychoacoustics. He understands both. Mr. Lucey does not”.
Source: https://gearspace.com/board/showpost.php?p=12959440&postcount=329
Note the choice of words, “improper listening tests”.
On many occasions – on ASR and previously elsewhere – Amir has claimed superior listening skills: https://www.whatsbestforum.com/thre...gher-resolution-audio-sounds-different.15255/
If Amir can realiably hear differences between resolution in files of CD quality and higher, it would make him stand out among the 350 people Mark Waldrep tested using his own production files in the test (in fact, the only one who had a 100 percent score cheated by using his eyes on a meter):
 www.realhd-audio.com
www.realhd-audio.com
It’s important to have this background in mind – i.e. Amir’s claim that his hearing is superior to experienced mastering engineers and Grammy winners – when reviewing his reviews. He claims to hear what others cannot.
Amir has always stated that blind testing is the gold standard in audio science. But when he started doing speaker tests, he insisted on doing those tests sighted and after he measured the speaker. After criticizing others for doing sighted tests, he insists on reviewing speakers both sighted – and after measuring the speaker too. In other words, he has more information on hand before he writes his review than the reviewers he normally criticizes. The whole idea of blind listening is to minimize bias and let nothing but the sound influence one’s verdict.
Amir’s reviews are divided into two parts. One part is objective, the other subjective. Based on objective measurements done with a Klippel Near Field Scanner (NFS), another ASR member combines the Klippel NFS data with Harman’s algorithm (Harman is known for the works of Floyd Toole and Sean Olive) to calculate the speaker’s preference score. It’s important to have in mind that Amir doesn’t calculate the Harman preference score himself even if he used to call Toole’s and Olives’s work at Harman “the gold standard of audio science”. It’s due to an ASR member’s efforts that we have the Harman preference scores of each speaker Amir tested. The preference scores on ASR are not Amir’s effort and it was never Amir’s intention to calculate an objective preference score.
Instead of an objective speaker score, Amir decided to give the reviewed speakers a subjective score between 1 and 4. Because we have Amir’s subjective score and the objective score based on Harman’s preference algorithm, we can compare the two; we can compare how Amir’s subjective review stands against the objective data. All data comes from this link which sums up the subjective and objective score of all speakers tested on ASR:

 docs.google.com
docs.google.com
In total, 119 speakers have both subjective and objective scores. I will look at the objective scores without a subwoofer, but the analysis wouldn’t look different if I looked at the objective scores with subwoofer.
I have attached 2 pictures for the purpose of reviewing Audio Science Review. The following are comments of each picture.
FIGURE 1: This figure compares Amir’s subjective score with the objective score based on measurements and Harman’s preference algorithm. On the horizontal x axis, we have Amir’s subjective score from 1 to 4. On average, speakers that were subjectively least preferred by Amir, i.e. speakers with a score of 1, had an objective score of 2.8. Speakers with a subjective score of 2 had on average objective score of 3,7, speakers with a subjective score of 3 had an objective score of 4,6 and the most preferred speakers with a subjective score of 4 had an objective score of 5.2. There is a positive correlation between Amir’s subjective opinion and the objective measurements. But this correlation needs to be put in perspective. If we look at the standard deviation in the data series, we can illustrate the standard error of the previous objective scores. The least preferred speakers had an average objective score of 2.8 but the standard deviation around the mean is 1.5. Lines are drawn above and below the mean figure to illustrate the distribution around the mean.
If we look at Amir’s subjective scores, we will find that 22 speakers have been given a score of 1, 38 speakers got a subjective 2, 41 speakers got a subjective 3 and 18 speakers got a subjective top rating of 4. Amir’s mean subjective score is 2.5 and the standard deviation around this mean is 1. Exactly 2/3 of the reviews are given to the mid scores of 2 and 3, which leaves 1/3 for the tails, i.e. 1 and 4. Every time Amir increases his subjective rating one notch, this move represents a move of one standard deviation. This indicates that a speaker that got a subjective score of 4 is two standard deviations better than a speaker that got a subjective score of 2. From 1 to 4 is three standard deviations, and so on. To recap statistics 101: One standard deviation allows outliers that represent about 1/3 of the population, two standard deviations have 5 percent outliers in the data set and three standard deviations have 0,3 percent outliers.
Have in mind, however, that an Amir score of 2 and 3 could be very close. The lowest score could be 2,49 and the highest score could be 2,51. Due to rounding it’s hard to tell which speakers are subjectively very close. The above discussion of standard deviations in Amir’s subjective ratings need to take this point into account. From 1 to 4 is technically speaking 3 standard deviation but could in fact be just a little over 2 standard deviations.
Figure 1 reveals that there is overlap in objective measurements between speakers that got top and bottom ratings by Amir. This tells us that a speaker which scored very low on the objective measurement can get a high subjective rating by Amir. The most extreme conflict between Amir’s subjective opinion and the objective measurement is Revel M55XC. Amir gave the Revel speaker a 4, while the objective measurement was as low as 2.2, indicating that the objective measurements uncovered severe flaws in the Revel speaker. It’s well known that Amir is a dealer in Harman products (https://www.madronadigital.com/our-team) and knows the Harman sound very well. On the other extreme, Amir subjectively beheaded the Elac Uni-Fi 2.0, giving the speaker a 1 while the objective measurement said 5,6. The average objective score of all 120 speakers is 4.1, and the standard deviation is 1.7. In both of these cases Amir has given the mentioned speakers a score which is 1.5 standard deviations from his mean rating – and his score went in the opposite direction of the objective score and measurement of speakers that were about one standard deviation better and worse than the average measured speaker.
Because figure 1 indicates that Amir’s subjective opinion may be in conflict with the measured speaker performance, we need to look closer at the emerging hypothesis that Amir’s subjective listening is so much in conflict with the measurements that his listening, the objective measurements or the research by Harman cannot be trusted.
FIGURE 1

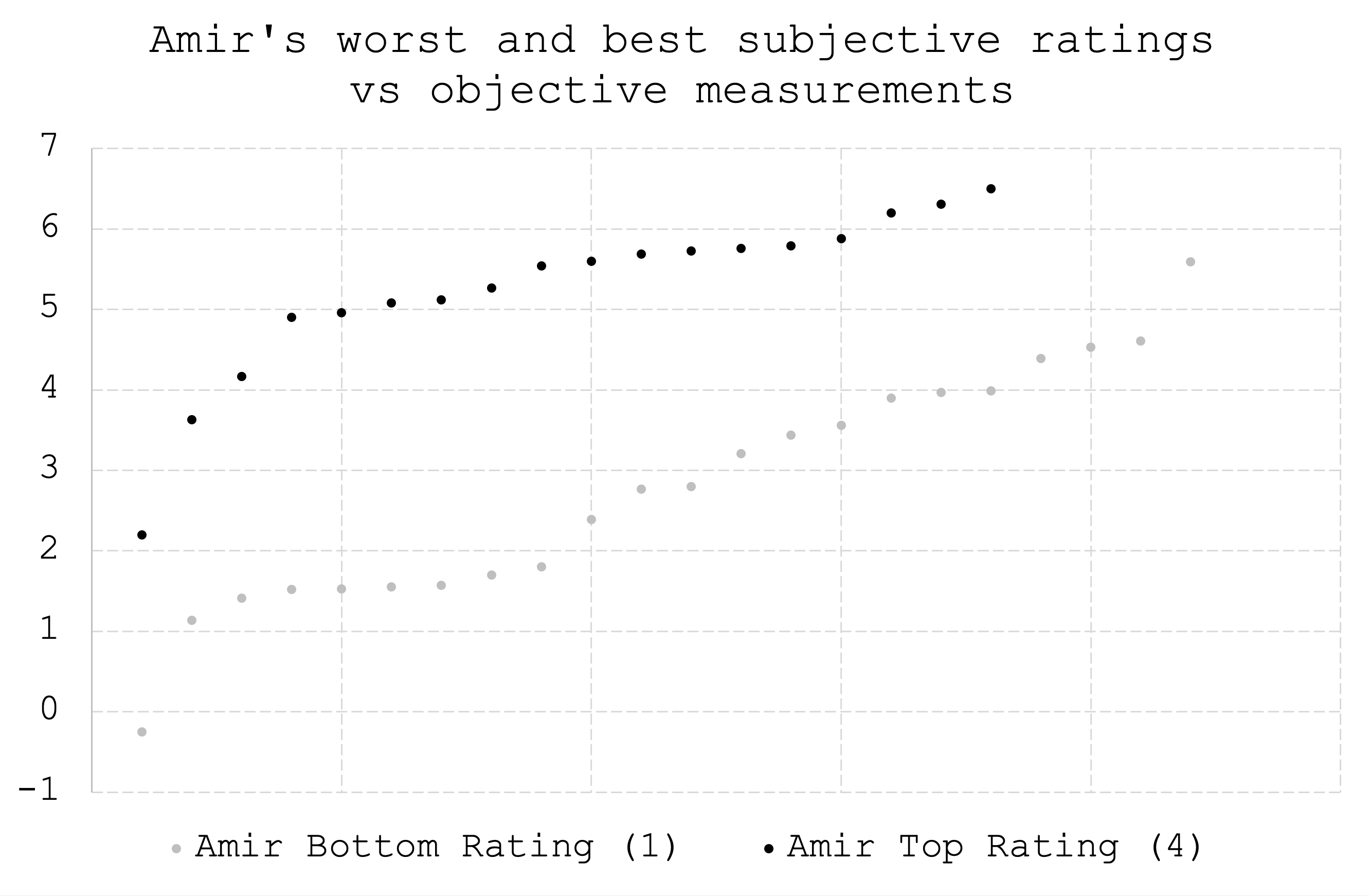
FIGURE 2: This figure shows Amir’s least preferred speakers (grey dots given a subjective score of 1) and most preferred speakers (black dots given a subjective score of 4) vs. the speakers’ measured performance. Even if there are 2-3 standard deviations between a subjective score of 1 and 4, we see that there is overlap in measured, objective performance. It means that when Amir says that a speaker is extremely bad by his subjective opinion, it could be extremely good based on measurements. And when Amir says a speaker is extremely good, it could be really bad based on measurements.
FIGURE 2
DISCUSSION: Amir and ASR put blind testing above all. Blind testing is the gold standard of science, according to Amir. However, when Amir started measuring speakers, he insisted on not only doing all reviews sighted. He also measured the speaker before making his verdict, which means Amir has more information on hand (he doesn’t have the Harman algorithm data, though, even if he has all the raw data for calculating the preference score) than any ordinary subjective reviewer before making his final verdict. Because knowing both the speaker and its measurements loads the reviewer with information that works as a bias or an anchor, it’s not surprising that we see a positive correlation on average between Amir’s subjective opinion and the objective measurements. But there is about a 50 percent overlap between the objective scores of speakers that Amir rated top (1) and bottom (2). This is an unexpected result if the measurements are correct, the research that went into the objective score is sound and if Amir’s hearing is superior. We would expect the extreme ratings of 1 and 2 of Amir to be confirmed by objective scores that are further apart than what is shown in the data.
There are several moving parts in this discussion that need to be understood to make a fair assessment. The Klippel NFS, the Harman algorithm and Amir are independent factors in this analysis that could in isolation or by combination make any analysis fruitless.
The Klippel NFS machine is serious work. Professor Wolfgang Klippel is a well-known person in audio. Therefore, I believe one for the purpose of this analysis can trust the Klippel NFS machine.
When it comes to the Harman algorithm and the work of Harman researchers like Toole and Olive, everyone in audio knows this work, its strengths and limits. While a discussion of the Toole and Olive work is always interesting, it’s hard to believe that the data from the Klippel NFS machine will be totally twisted and useless after going through the Harman algorithm.
The last factor in the analysis is Amir. Amir is a new kid on the audio block. Even if he calls his site Audio Science Review I found little evidence that Amir has a scientific background. He has written twice in the Journal of the Audio Engineering Society. Both times he wrote in the readers’ comments section, and in both comments he defended Bob Stuart in a discussion with another AES member. I believe anyone who paid his or her AES fees can comment in the readers’ comments section:
 secure.aes.org
secure.aes.org
Ouf of the three – Klippel, Harman research and Amir – which one is the weakest link in the chain? Who is the x factor in the analysis?
A defining mark of good scientists is that they go to great pains to distinguish between what they know and what they don’t know. This means one should keep the door open for the possibility that Amir’s hearing is better than measurements and the algorithm that was developed by Harman. However, this scenario’s plausibility isn’t strengthened by the fact that Amir previously said that Harman’s and Olive-Toole’s research is the gold standard in audio research. And why did Amir buy a very expensive Klippel Near Field Scanner if his hearing is better than the machine? Maybe Amir’s goal is to prove that his hearing is beyond science and measurement equipment, and the data I just went through is evidence that Amir is indeed one of a kind? What do you think?
CONCLUSION: “Truth is the daughter,” said Francis Bacon, “not of authority but time.” After subjective and objective reviews of 119 speakers, time has come for a review of the reviewer. The review supports the hypothesis that Amir’s hearing cannot be trusted.
Teksten er på engelsk og ble nettopp publisert på Gearspace (https://gearspace.com/board/showpost.php?p=15445069&postcount=117).
Synes du teksten er lang, hopp ned til «conclusion».
- - - - - - - - - - - - - - - - - - - - -
EMPEROR’S NEW CLOTHES
Much has been said here about Amir and Audio Science Review. Because science is supposedly a self-correcting community of experts who constantly check each other’s work, I think it’s time to post a review of Amir’s speaker reviews. Amir bans critical people from his own site so I will post my review here (he just recently banned a user, GoldenOne, for making a critical review of MQA: https://www.audiosciencereview.com/...i-published-music-on-tidal-to-test-mqa.22549/).
To provide some background I think it’s interesting that Amir has ridiculed members of this forum many times, even here on Gearspace. In a discussion on MQA – the lossy, compressed audio format of Bob Stuart’s MQA Ltd. – he ridicules Brian Lucey’s hearing.
“I am not worried about what Bob has created. I am worried about technical mumbo jumbo and improper listening test results proffered as a serious attempt to counter the work of MQA. As I have said, before you guys go after the likes of Bob Stuart, you need to hire someone who can spell signal processing and psychoacoustics. He understands both. Mr. Lucey does not”.
Source: https://gearspace.com/board/showpost.php?p=12959440&postcount=329
Note the choice of words, “improper listening tests”.
On many occasions – on ASR and previously elsewhere – Amir has claimed superior listening skills: https://www.whatsbestforum.com/thre...gher-resolution-audio-sounds-different.15255/
If Amir can realiably hear differences between resolution in files of CD quality and higher, it would make him stand out among the 350 people Mark Waldrep tested using his own production files in the test (in fact, the only one who had a 100 percent score cheated by using his eyes on a meter):
Find an Expert, Lose the Sales Pitch! – Real HD-Audio
It’s important to have this background in mind – i.e. Amir’s claim that his hearing is superior to experienced mastering engineers and Grammy winners – when reviewing his reviews. He claims to hear what others cannot.
Amir has always stated that blind testing is the gold standard in audio science. But when he started doing speaker tests, he insisted on doing those tests sighted and after he measured the speaker. After criticizing others for doing sighted tests, he insists on reviewing speakers both sighted – and after measuring the speaker too. In other words, he has more information on hand before he writes his review than the reviewers he normally criticizes. The whole idea of blind listening is to minimize bias and let nothing but the sound influence one’s verdict.
Amir’s reviews are divided into two parts. One part is objective, the other subjective. Based on objective measurements done with a Klippel Near Field Scanner (NFS), another ASR member combines the Klippel NFS data with Harman’s algorithm (Harman is known for the works of Floyd Toole and Sean Olive) to calculate the speaker’s preference score. It’s important to have in mind that Amir doesn’t calculate the Harman preference score himself even if he used to call Toole’s and Olives’s work at Harman “the gold standard of audio science”. It’s due to an ASR member’s efforts that we have the Harman preference scores of each speaker Amir tested. The preference scores on ASR are not Amir’s effort and it was never Amir’s intention to calculate an objective preference score.
Instead of an objective speaker score, Amir decided to give the reviewed speakers a subjective score between 1 and 4. Because we have Amir’s subjective score and the objective score based on Harman’s preference algorithm, we can compare the two; we can compare how Amir’s subjective review stands against the objective data. All data comes from this link which sums up the subjective and objective score of all speakers tested on ASR:
Speaker Data (beta)
In total, 119 speakers have both subjective and objective scores. I will look at the objective scores without a subwoofer, but the analysis wouldn’t look different if I looked at the objective scores with subwoofer.
I have attached 2 pictures for the purpose of reviewing Audio Science Review. The following are comments of each picture.
FIGURE 1: This figure compares Amir’s subjective score with the objective score based on measurements and Harman’s preference algorithm. On the horizontal x axis, we have Amir’s subjective score from 1 to 4. On average, speakers that were subjectively least preferred by Amir, i.e. speakers with a score of 1, had an objective score of 2.8. Speakers with a subjective score of 2 had on average objective score of 3,7, speakers with a subjective score of 3 had an objective score of 4,6 and the most preferred speakers with a subjective score of 4 had an objective score of 5.2. There is a positive correlation between Amir’s subjective opinion and the objective measurements. But this correlation needs to be put in perspective. If we look at the standard deviation in the data series, we can illustrate the standard error of the previous objective scores. The least preferred speakers had an average objective score of 2.8 but the standard deviation around the mean is 1.5. Lines are drawn above and below the mean figure to illustrate the distribution around the mean.
If we look at Amir’s subjective scores, we will find that 22 speakers have been given a score of 1, 38 speakers got a subjective 2, 41 speakers got a subjective 3 and 18 speakers got a subjective top rating of 4. Amir’s mean subjective score is 2.5 and the standard deviation around this mean is 1. Exactly 2/3 of the reviews are given to the mid scores of 2 and 3, which leaves 1/3 for the tails, i.e. 1 and 4. Every time Amir increases his subjective rating one notch, this move represents a move of one standard deviation. This indicates that a speaker that got a subjective score of 4 is two standard deviations better than a speaker that got a subjective score of 2. From 1 to 4 is three standard deviations, and so on. To recap statistics 101: One standard deviation allows outliers that represent about 1/3 of the population, two standard deviations have 5 percent outliers in the data set and three standard deviations have 0,3 percent outliers.
Have in mind, however, that an Amir score of 2 and 3 could be very close. The lowest score could be 2,49 and the highest score could be 2,51. Due to rounding it’s hard to tell which speakers are subjectively very close. The above discussion of standard deviations in Amir’s subjective ratings need to take this point into account. From 1 to 4 is technically speaking 3 standard deviation but could in fact be just a little over 2 standard deviations.
Figure 1 reveals that there is overlap in objective measurements between speakers that got top and bottom ratings by Amir. This tells us that a speaker which scored very low on the objective measurement can get a high subjective rating by Amir. The most extreme conflict between Amir’s subjective opinion and the objective measurement is Revel M55XC. Amir gave the Revel speaker a 4, while the objective measurement was as low as 2.2, indicating that the objective measurements uncovered severe flaws in the Revel speaker. It’s well known that Amir is a dealer in Harman products (https://www.madronadigital.com/our-team) and knows the Harman sound very well. On the other extreme, Amir subjectively beheaded the Elac Uni-Fi 2.0, giving the speaker a 1 while the objective measurement said 5,6. The average objective score of all 120 speakers is 4.1, and the standard deviation is 1.7. In both of these cases Amir has given the mentioned speakers a score which is 1.5 standard deviations from his mean rating – and his score went in the opposite direction of the objective score and measurement of speakers that were about one standard deviation better and worse than the average measured speaker.
Because figure 1 indicates that Amir’s subjective opinion may be in conflict with the measured speaker performance, we need to look closer at the emerging hypothesis that Amir’s subjective listening is so much in conflict with the measurements that his listening, the objective measurements or the research by Harman cannot be trusted.
FIGURE 1
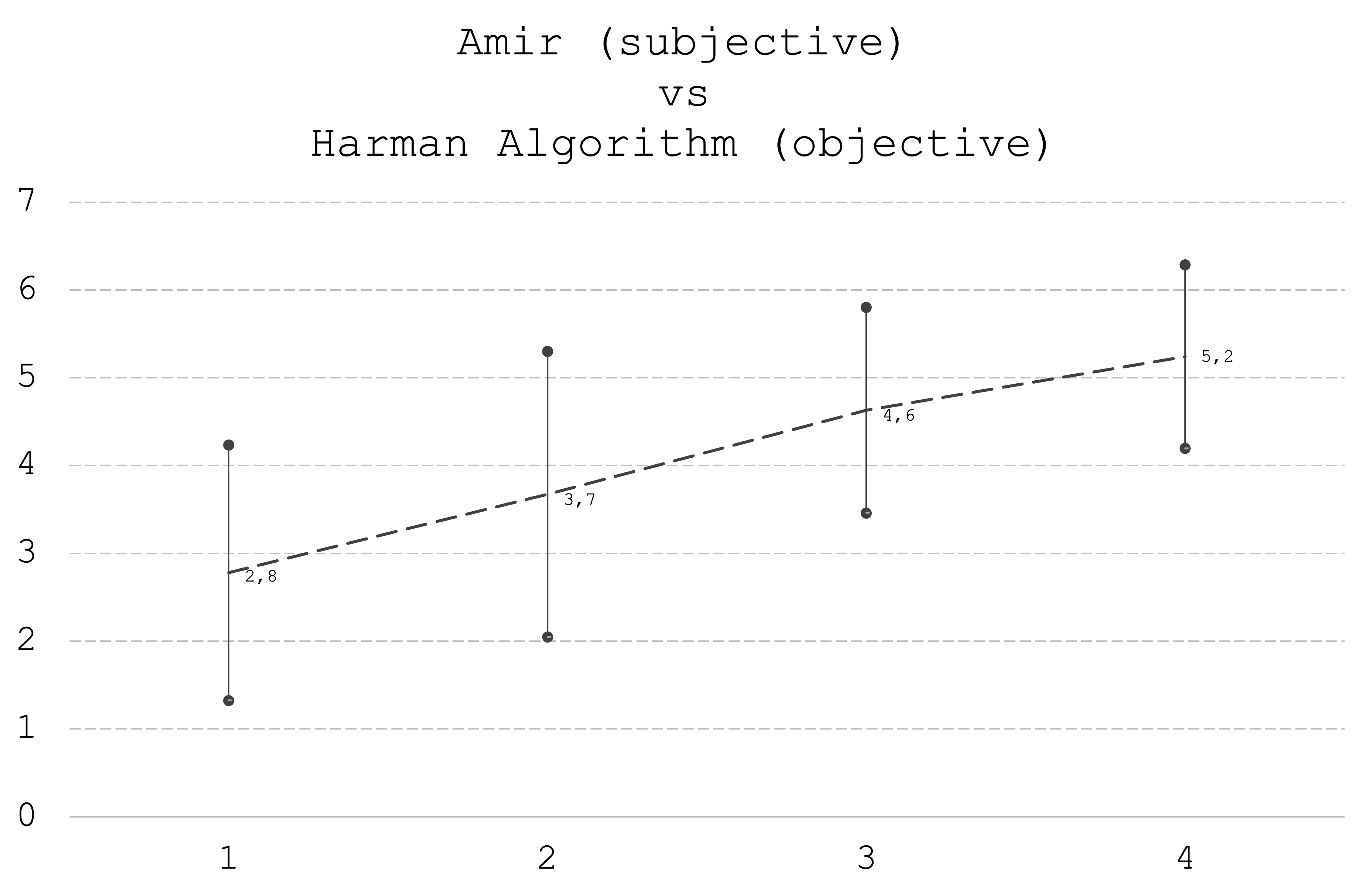
FIGURE 2: This figure shows Amir’s least preferred speakers (grey dots given a subjective score of 1) and most preferred speakers (black dots given a subjective score of 4) vs. the speakers’ measured performance. Even if there are 2-3 standard deviations between a subjective score of 1 and 4, we see that there is overlap in measured, objective performance. It means that when Amir says that a speaker is extremely bad by his subjective opinion, it could be extremely good based on measurements. And when Amir says a speaker is extremely good, it could be really bad based on measurements.
FIGURE 2
DISCUSSION: Amir and ASR put blind testing above all. Blind testing is the gold standard of science, according to Amir. However, when Amir started measuring speakers, he insisted on not only doing all reviews sighted. He also measured the speaker before making his verdict, which means Amir has more information on hand (he doesn’t have the Harman algorithm data, though, even if he has all the raw data for calculating the preference score) than any ordinary subjective reviewer before making his final verdict. Because knowing both the speaker and its measurements loads the reviewer with information that works as a bias or an anchor, it’s not surprising that we see a positive correlation on average between Amir’s subjective opinion and the objective measurements. But there is about a 50 percent overlap between the objective scores of speakers that Amir rated top (1) and bottom (2). This is an unexpected result if the measurements are correct, the research that went into the objective score is sound and if Amir’s hearing is superior. We would expect the extreme ratings of 1 and 2 of Amir to be confirmed by objective scores that are further apart than what is shown in the data.
There are several moving parts in this discussion that need to be understood to make a fair assessment. The Klippel NFS, the Harman algorithm and Amir are independent factors in this analysis that could in isolation or by combination make any analysis fruitless.
The Klippel NFS machine is serious work. Professor Wolfgang Klippel is a well-known person in audio. Therefore, I believe one for the purpose of this analysis can trust the Klippel NFS machine.
When it comes to the Harman algorithm and the work of Harman researchers like Toole and Olive, everyone in audio knows this work, its strengths and limits. While a discussion of the Toole and Olive work is always interesting, it’s hard to believe that the data from the Klippel NFS machine will be totally twisted and useless after going through the Harman algorithm.
The last factor in the analysis is Amir. Amir is a new kid on the audio block. Even if he calls his site Audio Science Review I found little evidence that Amir has a scientific background. He has written twice in the Journal of the Audio Engineering Society. Both times he wrote in the readers’ comments section, and in both comments he defended Bob Stuart in a discussion with another AES member. I believe anyone who paid his or her AES fees can comment in the readers’ comments section:
AES Convention Papers Forum » The Audibility of Typical Digital Audio Filters in a High-Fidelity Playback System
The AES Forum is where our members get to interact with each other in between conferences and section meetings.
Ouf of the three – Klippel, Harman research and Amir – which one is the weakest link in the chain? Who is the x factor in the analysis?
A defining mark of good scientists is that they go to great pains to distinguish between what they know and what they don’t know. This means one should keep the door open for the possibility that Amir’s hearing is better than measurements and the algorithm that was developed by Harman. However, this scenario’s plausibility isn’t strengthened by the fact that Amir previously said that Harman’s and Olive-Toole’s research is the gold standard in audio research. And why did Amir buy a very expensive Klippel Near Field Scanner if his hearing is better than the machine? Maybe Amir’s goal is to prove that his hearing is beyond science and measurement equipment, and the data I just went through is evidence that Amir is indeed one of a kind? What do you think?
CONCLUSION: “Truth is the daughter,” said Francis Bacon, “not of authority but time.” After subjective and objective reviews of 119 speakers, time has come for a review of the reviewer. The review supports the hypothesis that Amir’s hearing cannot be trusted.



