
Målbare forskjeller på kabler.
- Trådstarter mutz
- Startdato
Diskusjonstråd Se tråd i gallerivisning
-

@Asbjørn...kan det være en problemstilling med varmegang i høyttaler spoler og kraftige forsterkere (A, D og AB) på flere 1000 watt i 8 ohm som kan levere spisseffekt opp mot 10-12 000 watt?Fordi det er strømstyrke og oppvarming som dimensjonerer i mye annen elektroteknikk. Når man skal overføre veldig mange ampere er det viktig å vite hvilket tverrsnitt man har tilgjengelig. Varmgang er bare ikke en problemstilling i hifi.Pparafinoksen
Gjest
Nå fjaser du fælt, Valentino.Jepp. Men det er veldig kjekt at det finnes mennesker som er i stand til å konstruere de dingsene som trenges for å kose seg med musikk, er det ikke? Nå er dagens simulatorer svært nøyaktige, og kan settes opp til å simulere det meste av arbeidssituasjoner, men dette er såpass avansert at 'brødhuer' nok ikke har en sjangs til å sette opp dette. Konstruksjon og topologi må man fortsatt står for selv, så det vil selvsagt også avspeile kunnskapen til
Nå er dagens simulatorer svært nøyaktige, og kan settes opp til å simulere det meste av arbeidssituasjoner, men dette er såpass avansert at 'brødhuer' nok ikke har en sjangs til å sette opp dette. Konstruksjon og topologi må man fortsatt står for selv, så det vil selvsagt også avspeile kunnskapen til
'konstruktøren'. Hva angår kapasitans og induktans, så skjønner jeg ikke hva som er problemet, - det er fortsatt kjente størrelser og parametre som ligger til grunn for seriøse konstruksjoner, og ikke kvasivitenskapelige meninger og påstander fra HiEnd-miljøet...Sist redigert:
Jepp, utrolig kjekt faktisk!! Jeg ELSKER de menneskeneJepp. Men det er veldig kjekt at det finnes mennesker som er i stand til å konstruere de dingsene som trenges for å kose seg med musikk, er det ikke?

Ja, det kan det jo. Effekten vil varme opp kobbertråden i høyttalermotoren og øke seriemotstanden, men det behøves ikke mange kilowatt. Ingen høyttaler overlever det. Noen titalls watt over litt tid holder i massevis til å brenne av en høyttalermotor.@Asbjørn...kan det være en problemstilling med varmegang i høyttaler spoler og kraftige forsterkere (A, D og AB) på flere 1000 watt i 8 ohm som kan levere spisseffekt opp mot 10-12 000 watt?
Speaker Failure Analysis
ESP - The Audio Pages. An analysis of speaker driver failure with particular reference to high powered audio systems as seen in the worlds of Sound Reinforcement and Discosound-au.com
På veien til en termisk død vil det også låte annerledes. En motor som har 5 ohm resistans ved romtemperatur vil ha 7 ohm ved 120 grader, tilsvarende ganske mange meter høyttalerkabel. Det gir termisk kompresjon og eventuelle passive delefiltre vil endre delefrekvenser og flankesteilheter. Men det er ingen ting du kan gjøre med det i en passiv høyttaler.
Passive Crossover Network Design
ESP - The Audio Pages. Tips and techniques for passive crossover network design, including a design spreadsheet. Much more information than you are used to on this topic.sound-au.com
Sist redigert:
Supert, takk for svar Asbjørn...da ble man litt kokere.Ja, det kan det jo. Effekten vil varme opp kobbertråden i høyttalermotoren og øke seriemotstanden, men det behøves ikke mange kilowatt. Ingen høyttaler overlever det. Noen titalls watt over litt tid holder i massevis til å brenne av en høyttalermotor.
Speaker Failure Analysis
ESP - The Audio Pages. An analysis of speaker driver failure with particular reference to high powered audio systems as seen in the worlds of Sound Reinforcement and Disco
På veien til en termisk død vil det også låte annerledes. En motor som har 5 ohm resistans ved romtemperatur vil ha 7 ohm ved 120 grader, tilsvarende ganske mange meter høyttalerkabel. Det gir termisk kompresjon og eventuelle passive delefiltre endre delefrekvenser og flankesteilheter. Men det er ingen ting du kan gjøre med det i en passiv høyttaler.
Passive Crossover Network Design
ESP - The Audio Pages. Tips and techniques for passive crossover network design, including a design spreadsheet. Much more information than you are used to on this topic.
 Et par sekund tok det på diskantene mine da de ble foret av en 12khz sinus tone og et par tre hundre watt. Fadet fort ut og kjent svidd lukt kom
Et par sekund tok det på diskantene mine da de ble foret av en 12khz sinus tone og et par tre hundre watt. Fadet fort ut og kjent svidd lukt kom
En klassisk generaltabbe å fyre opp etter å ha jittermålt dac/streamer
Response_to_ASR_comments.pdf (sc.edu)
We have a “critical assessment” of journal papers from someone who never published a single research paper himself! Mr. Majidimehr [Amir] has no clue about how scientific research works.
Apollo 11 was not an admission of “mistakes” by the first 10 missions because they didn’t land people on the moon. The earlier missions set the stage. Having never published any research at all, Mr. Majidimehr would not know this.
Mr. Majidimehr has serious deficits in his understanding of key concepts.
Milind N. KunchurSist redigert:PPowercon
Gjest
Han ble ordentlig furten gitt han fyren som skrev den publikasjonen som Amir plukket litt istykker.
Rett ned i forsvar og sverte person fremfor å bevise sak.
Ikke plagsomt scientific som han selv føler så sterkt for.
Hva mener du han skulle bevise? Kunchur har pekt på fem punkter hvor han underbygger at Amir har " serious deficits in his understanding". Han viser til og med hvor Amir kan finne informasjon i notatet han tydeligvis ikke fant ved sin gjennomlesning. Når man publiserer slik pseudovitenskap for sine følgere så må det svares på. Men å bevise sin sak som du skriver. Det gjør man i vitenskapelige publikasjoner.Han ble ordentlig furten gitt han fyren som skrev den publikasjonen som Amir plukket litt istykker.
Rett ned i forsvar og sverte person fremfor å bevise sak.
Ikke plagsomt scientific som han selv føler så sterkt for.
Nå er det vel heller ikke mange som mener at det vitenskap Amir driver med, heller enn å påpeke direkte feil i påstandene til vidundermakerne..PPowercon
Gjest
Artig tanke. Hvor mange slike vitenskapelige publikasjoner tror du diverse hifi-produsenter har skrevet for å bevise sine påstander om fantastisk bedre lyd++ ved å kjøpe X merke amp/dac/kabler/strømrensere?Når man publiserer slik pseudovitenskap for sine følgere så må det svares på. Men å bevise sin sak som du skriver. Det gjør man i vitenskapelige publikasjoner.
Eller er det bare denne Amir som skal utgi vitenskapelige publikasjoner når han plukker istykker påstander fra hifi-produsenter etc?I tittelen fremgår det at dette er et oppgjør mot Amirs pseudovitenskap og slakter ham selvsagt for sin overfladiske kritikk av en vitenskapelig publikasjon. Harde og fortjente ord.
Edit: Svarte på et innlegg som er slettet.Sist redigert:PPowercon
Gjest
Det betyr vel at disse som utgir sånne publikasjoner også må tåle harde og fortjente ord om innholdet ikke holder mål.?I tittelen fremgår det at dette er et oppgjør mot Amirs pseudovitenskap og slakter ham selvsagt for sin overfladiske kritikk av en vitenskapelig publikasjon. Harde og fortjente ord.
Merk at Amir ikke gikk etter de som lagde publikasjonen, men selve arbeidet som ble presentert.
Et generelt krav i slike vitenskapelige tester (og påfølgende publikasjoner)at testene dokumenteres og kan repeteres, både på gjennomførelse og resultat.
Var vel ikke så mye av det i den publikasjonen. -Eks "Røska frem tre kabler i ca samme lengde og i antatt ulik kvalitet og testet dem", er ikke vitenskapelig på noen måte.
Amir plukker fort ned sånne low hanging fruits som det heter.
Uansett resultat, Amirs testing kan fint ettergås og repeteres av andre. Han viser hva og hvordan i reviews og med utdypende forklaring på video på utvalgte saker.
Om man liker eller ikke liker resultatene er nå så, men skjønner det ofte kan være vanskelig å gå på sak enn mannen.
- Ble medlem
- 11.11.2006
- Innlegg
- 20.772
- Antall liker
- 31.517
- Sted
- Kjelleren i kroken
- Torget vurderinger
- 2
Så mye krangling og sur stemming, den mest faktabaserte målbare sannhet angående kabler er lengden...PPowercon
Gjest
Det tok de aller fleste ut ifra den texten du hadde klippet ut.^ Og samtidig vet jeg at Powercon faktisk må ha lest responsen til ASR fra Dr. Kunchur siden han klaget på at Kunchur var ordentlig furten når han skrev den
Men ja, jeg har skumlest den.Sist redigert av en moderator:PPowercon
Gjest
Men jeg synes å ha fått med meg at mange av de som ikke stoler på målinger, likevel ofte stoler på en måling: Nemlig vekta på amp/dac.Så mye krangling og sur stemming, den mest faktabaserte målbare sannhet angående kabler er lengden...
- Ble medlem
- 11.11.2006
- Innlegg
- 20.772
- Antall liker
- 31.517
- Sted
- Kjelleren i kroken
- Torget vurderinger
- 2
Hvis en forsterker måler/veier 40kg, så stoler jeg på det - lydmessig eller kvaliteten vet jeg ingenting om.Men jeg synes å ha fått med meg at mange av de som ikke stoler på målinger, likevel ofte stoler på en måling: Nemlig vekta på amp/dac.
Hvis en kabel måler 2 meter, så stoler jeg på det - lydmessig eller kvaliteten vet jeg ingenting om.PPowercon
Gjest
Var en generell kommentar.
Mange produsenter forteller jo villig vekk i reklamen at produkt X veier Y kg og dette tilsier at den er av ordentlig kvalitet og seriøs hifi. Aka må veie litt før det er kvalitet.
Det finnes (flere av) dem som sverger til stor kvadrat på sine kabler. Sånn sett kan de måle kvalitet med forholdet av lengde og vekta.Hvis en forsterker måler/veier 40kg, så stoler jeg på det - lydmessig eller kvaliteten vet jeg ingenting om.
Hvis en kabel måler 2 meter, så stoler jeg på det - lydmessig eller kvaliteten vet jeg ingenting om.
Kabel-kvalitet = masse/lengde [kg/m]

 Dette er usedvanlig svakt arbeid og Amir påpeker en rekke høyst relevante poenger. Synes fyren lagde sitt "scientific paper" utelukkende basert på å la bekreftelsesbias få herje fritt.
Dette er usedvanlig svakt arbeid og Amir påpeker en rekke høyst relevante poenger. Synes fyren lagde sitt "scientific paper" utelukkende basert på å la bekreftelsesbias få herje fritt.
Spesielt interessant er det når han hevder at vi fra rene 900Hz toner (eller lavere) kan detektere om lydkilden på 3 meters avstand flytter seg 3 meter til siden. Greit nok at vi kan plassere impulser presist, men ikke toner. Det er i det heletatt ganske interessant at han trekker ITD inn i forbindelse med sinustoner. Vi er ikke veldig gode på å detektere faseforskjeller på ørene, spesielt ikke faseforskjeller på 3 grader.
Jeg finner det også ganske interessant at han bruker så mange adjektiver på å "møte kritikken". Hele den første siden virker å være et rent personangrep på Amir. Han blander også inn en stor dose massesuggesjon der for eksempel det at hans paper ikke har vært kritisert og ingen feil har vært funnet. Jeg kan bare snakke for meg selv, men jeg var ikke klar over at noe slikt lå ute for åpen reveiw, men jeg kan love at jeg hadde hatt noe å innvende. Da må man nesten spørre seg hvor mange andre som hadde hatt noe å innvende, hadde de visst om dette.
Uansett, jeg synes oppførselen hans virker tullete, og jeg mener hans paper er kritikkverdig fordi (og dette er nøyaktig hva Amir har påpekt):
Det han har målt er nøyaktig i tråd med LCR-modellen. Vi vet at L, C og R på mikroskopisk nivå ikke er linjære, som vi "alltid" har visst. Vi vet at for å få frem dette mått han ha kilde og mottakerimpedans i megaohm-klassen, noe som åpenbart aldri skjer i praksis. Vi ser at alle målingene ser ut til å stemme med de ulinjære LCR-modellene. Vi ser at knaggene han har forsøkt å henge dette på handler om at han ikke helt har forstått de paperene han har støttet seg på. Ja kort sagt, dette bringer ingen ting nytt i saken. Det bekrefter at luft og teflon er bedre isolasjon enn andre plastmaterialer, og at svakt konduktive materialer for isolasjon vil gi mindre kryp i kapasistans. Vi ser at kabler som utsettes for enorme strømmer vil vibrere og få en feedback-effekt. Og vi vet alt dette fra før, vi vet hvordan vi designer kretser for å unngå at dette betyr noe som helst. Vi vet at det fortsatt ikke trenger å koste over 100kr/meter for den beste kabelen til oppgaven, og til slutt, vi vet at de små tingene han endte med å hevde at kan være halmstråene som gir hørbar forskjell rett og slett ikke er riktig tolkning av eksisterende forskning. Vi hører simpelthen ikke 3 grader fasedreining ved 900Hz, men vår ITD tillater at vi kan høre om en lydkilde flytter seg noen centimeter gitt at det er impulser involvert. Dette visste vi fra før, og vi vet at vi kan klare å skape denne tidsforskjellen enkelt med en liten spole, eller en tilstrekkelig induktiv kabel.
Så ja, dette er et makkverk av et paper, men det er heller ikke ofte det kommer et AES-paper som bringer noe nytt til torgs, og de fleste bærer preg av at "forskeren" ikke har mer kompetanse enn en "youtuber", for å bruke hans egen retorikk.
Hadde han tilbragt et par timer med en ingeniør hadde han sluppet å skrive dette paperet.
Hvorfor det? Amir sin kritikk treffer jo saklig sett riktig. Hvorfor er dette fortjent?Harde og fortjente ord.Kunchur har ikke bevist noen ting i sine "analyser" av kablene. Han beviste egentlig selv sin manglende innsikt allerede i gjennomføringen av sitt første "paper".
Jeg kikket på denne videoen av han nå, men orket ikke mer enn halvparten.
Kunchur viser tydelig her at han ikke vet hva han driver med. Jada, timing er viktig i audio, og ja, timing med en kortere tid enn tilsvarende periodetid for et signal på 20kHz er hørbart. Men han har lullet seg inn i en retorikk rundt dette med "timbre" og tid ned i sub us tider som ikke henger på greip i det hele tatt.Snickers-is, dette er vitenskaplig forskning hvor man underbygger sine påstander og viser til tidligere etablerte publikasjoner. EAS hadde i tillegg etablert en egen diskusjon rundt artikkelen hvor man kunne kommer med sine spørsmål på EAS sine sider.
Alle fem punktene som Kunchur påpekte svakheter i er underbygget med henvisninger. Det er da mer rett å så at han viser til... istedet for at han hevder...som du skriver.
De som er interessert i hva Kunchur er opptatt av kan låne øre til denne lærerike saken (23 min). Veldig spennende bl.annet om timbre og timing.
High End Audio and the Domain of Time - YouTube
Men gå gjerne til kildene som er oppgitte på temaet:
R. B. Klumpp, and H. R. Eady, “Some measurements of interaural time difference thresholds,” J.
Acoust. Soc. Am., vol. 28, pp. 859–860 (1956). DOI: 10.1121/1.1908493.
A. Brughera, L. Dunai, W. M. Hartmann, “Human interaural time difference thresholds for sine tones:
the high-frequency limit”, J Acoust Soc Am. vol. 133, no. 5, pp.2839-2855 (2013 May). Their Fig. 1(c).
DOI: 10.1121/1.4795778. PMID: 23654390; PMCID: PMC3663869.Mye av det som diskuteres er gjeldene vitenskap. Så er det teoriene som vi muligens ikke har en vitenskapelig «forståelse» og bevis ennå???
La oss håpe at vitenskapen går videre så det kan være en sjanse å finne ut av om de lydforskjellene mange hører er plasebo, eller reelt???
Jeg har fått høre at en del produsenter av «ymse» utstyr driver med egen forskning. Men holder kortene tett til brystet grunner konkurransefordeler ect.
Dette gjelder både videre utviklede målemetoder og audiovisuelle forskjeller…
Det det skorter på er etterprøvbare og repeterbare lyttetester som ev kan påvise at opplevde forskjeller skyldes lydtrykksvariasjonene som kommer inn i øregangen....
La oss håpe at vitenskapen går videre så det kan være en sjanse å finne ut av om de lydforskjellene mange hører er plasebo, eller reelt???
...
Det er ikke nødvendig med så mye vitenskaplige fremskritt ut over det.
mvh
KJ
Hvem er det som kontrollerer lytteren(e) før påstander kan verifiseres?Det det skorter på er etterprøvbare og repeterbare lyttetester som ev kan påvise at opplevde forskjeller skyldes lydtrykksvariasjonene som kommer inn i øregangen.
Finnes det vitenskapelig bevis for at den subjektive lydopplevelsen KAN være lik på 2 eller flere personer i et lyttepanel?
Skal en lyttetest utføres bør vel de elektriske forhold for hørbare forskjeller være tilstede? Og hvordan måle forskjellene? Hvor mange klarer å tolke målingene til Bollen?
Kabel lengde? Kvasi vitenskap?
Sist redigert:
Når det er svakheter i kildene skal jeg selvsagt forholde meg til dette. Men i dette tilfellet var det bare han selv som hadde laget sin egen tolkning av kildene og kom med sin egen påstand basert på dette som en slags sannhet.Snickers-is, dette er vitenskaplig forskning hvor man underbygger sine påstander og viser til tidligere etablerte publikasjoner. EAS hadde i tillegg etablert en egen diskusjon rundt artikkelen hvor man kunne kommer med sine spørsmål på EAS sine sider.
Alle fem punktene som Kunchur påpekte svakheter i er underbygget med henvisninger. Det er da mer rett å så at han viser til... istedet for at han hevder...som du skriver.
De som er interessert i hva Kunchur er opptatt av kan låne øre til denne lærerike saken (23 min). Veldig spennende bl.annet om timbre og timing.
High End Audio and the Domain of Time - YouTube
Men gå gjerne til kildene som er oppgitte på temaet:
R. B. Klumpp, and H. R. Eady, “Some measurements of interaural time difference thresholds,” J.
Acoust. Soc. Am., vol. 28, pp. 859–860 (1956). DOI: 10.1121/1.1908493.
A. Brughera, L. Dunai, W. M. Hartmann, “Human interaural time difference thresholds for sine tones:
the high-frequency limit”, J Acoust Soc Am. vol. 133, no. 5, pp.2839-2855 (2013 May). Their Fig. 1(c).
DOI: 10.1121/1.4795778. PMID: 23654390; PMCID: PMC3663869.
Når det gjelder knaggene han forsøker å henge dette på så er det i høyeste grad hans påstand.
Denne videoen er jo litt interessant, allerede i starten går han grundig på trynet når han deler opp musikk i 4. Man kan ikke behandle musikk som en kunstnerisk øvelse når man skal analysere signalteorien rundt det. Da må man forholde seg til det faktum at det er komplekse tall. Det er slik signalteorien fungerer og det er slik hjernen vår fungerer. Dette bør han vite når han bruker dotorgraden sin i denne sammenhengen.
Så skal han forklare at frekvensrespons ikke betyr noe særlig ved å bruke kombinasjonen av en fundamental og en overtone med ulik amplitude. Forskjellen er tydelig hørbar selv om forskjellen på de to bare er litt over 2dB. Han forsøker å snakke dette opp til å være en mye større forskjell ved å bruke den linjære forskjellen i prosent, mens han forsøker å manipulere lytteren til å tenke at "dette hører vi jo nesten ikke forskjell på", selv om det er svært tydelig. Man må gå ut fra at han egentlig vet at denne skalaen er logaritmisk, og i såfall er dette høyst påfallende. Hvis han ikke vet at det er en logaritmisk skala går det jo et godt stykke på veien til å stadfeste vesentlig kunnskapsmangel.
Så legger han inn en delay, og jeg må nok en gang understreke at dette handler om kabler og skal "simulere" forskjeller på i størrelsesorden 0,000000000001sekunder. Til dette bruker han en delay på 0,17 sekunder, bare 170 milliarder ganger større altså. Eller var det 5µs han skulle bevise her? I såfall er jo forskjellen bare 3400 ganger større enn det han skal bevise.
Så legger han inn en faseforskjell på 90 grader ved 880Hz. Forskjellen er hørbar, men dette er jo som forventet til forskjell ganske ubetydelig. Imidlertid skjuler det seg her den antakelig største generaltabben, for han har bare spleiset sammen signalene og velger å starte denne 880Hz tonen et annet sted på kurven. I virkeligheten, når vi har med å gjøre en fasefeil, skjer ikke dette. Fase feil kommer først og fremst direkte av forsinkelser og elektroakustiske inverteringer. Vi har ikke faseavvik på den måten han her demonstrerer. Det som gjør at dette er vesentlig er at i hans eksempel så tegnes starten på transienten (der sinusene starter) distinkt i begge tilfellene, mens i virkeligheten vil et faseavvik gjøre at man også får et tidsavvik på transientens begynnende flanke. Igjen, her må det understrekes at han skal ta dette videre til kabler. Her snakker vi med andre ord i størrelsesorden 0,0000001584 grader fasedreining. Det samme som å plassere høyttaleren 0,05mm for langt fra lytteren.
Så kommer vi til eksempelet med instrumenter, de to instrumentene har totalt ulikt frekvensinnhold og helt vilt forskjellig impulsrespons, og vi klarer å høre forskjell, ja, rart gitt. Dette visste vi ikke før Kunchur sin forskning kom på banen vel.
Også snur vi et anslag på et piano bak frem, og jaggu klarte jeg å høre forskjell på det.
Også klipper de bort deler av impulsen fra et instrument, og jaggu blir ikke lyden der plutselig vanskelig å kjenne igjen også!!!!??? Også sier vi bare "det er mer viktig enn å få frekvensspektrumet riktig... Hva pokker? Han har ikke bevist annet enn at det er andre ting som OGSÅ kan ødelegge lyden.
Så regner han ut hvor lang en signalperiode ved hhv 10 og 20kHz er. Også går han videre til å hevde at dette er "skeptikernes" versjon av hvor stor presisjon ørene våre har for timing. Hvor i all verden har han kokt i hop det?
Så hvordan vet vi at vi trenger mer enn 50-100µs presisjon? Jo, det kan vi visst bare ta produsentenes ord for, i dette tilfellet Wilson Audio. Men det er selvsagt et eksperiment som kan verifisere dette, nemlig to diskanter i en baffel som forskyves i forhold til hverandre, og liknende avvik i timing på hodetelefoner. Vent litt, hvordan ble disse eksperimentene gjennomført sa du? Hva var det de viste? Halloo?? Hopper du direkte over til å forklare hvordan øret virker uten å si noe mer?
Og hva er det du forsøker å si om øret? At det virker? Skulle du ikke underbygge påstandene dine Mr Kunchur? Og når du her begynner å snakke om at ett av disse hårene mottar 120dB mens et annet mottar en liten fraksjon av dette, er det ikke på høy tid å henvise til et paper om maskeringen som skjer når store og små ting foregår i lyden samtidig? Nei, du bare avviser diminishing returns fordi det passer deg, selv om det kræsjer med all forskning som har vært gjort på emnet?
Også tar vi "jeg har aldri hørt et 100% overbevisende oppsett"-argumentet. Jaha, men det er kabler vi snakker om her, eller? For du nevnte ikke at den høyttaleren du refererte til har en hel rekke delefrekvenser, masse forvrengning og lassevis med decay, men det er kanskje ikke så viktig når vi har LCR-parametere i kabler som kan forsinke signalet med opptil flere picosekunder, eller, for å sitere deg da, omkring 1/1000000 av det som i følge dine eksperimenter skal være minste tidsforskjell vi kan høre forskjell på? Nei, det er klart, da betyr jo ikke disse driverne noe som helst. Heller ikke passive filtere, delefrekvenser og slikt for det er selvsagt kablene sin skyld at du ikke har blitt overbevist om at hifi låter 100% ekte. Skal vi ta innspillingsteknikk med det samme? Tror vi lar det ligge. Man skal ikke sparke noen som ligger nede har jeg hørt.
Og nei Mr Kunchur, det finnes ikke bevis for at noen kan høre 0dB. Heller ikke 10dB. 0dB er et teoretisk grense. Get your facts straight.
Flowchart av hjernen? Kom igjen a, er du SÅ tom for argumenter? Octopus-neuroner? Den første frekvensen lekker ut før de andre ankommer? Og tidsforskjellene er mindre enn 1/10 signalperiode i beste fall, eller i ditt eget eksempel (900Hz) mindre enn 1/220 signalperiode... Kjære vene, de signalene som kommer inn i en sånn ligger innenfor ca 1/8 tonehøyde. Skal kablene dine ha timingfeil innenfor et bånd på 1/8 tonehøyde ved 900Hz?
Konklusjonene til Mr Kunchur går som følger:
- High End Audio er mye bedre enn typisk consumer audio...
Vel, ja, i mange tilfeller er det riktig, er ikke det litt av poenget?
- Forskjellene i ytelse i High End Audiosystemer er ikke relatert til forskjeller i frekvensrespons og harmonisk forvrengning. I stedet hva som gjør dem forskjellig er ting som skjer i tidsdomenet, samt enkelte typer støy...
Jaha? Hvilke typer støy? Men i mye consumer audio sitter nøyaktig samme innmat som i disse high end tingene. I tillegg har du jo ikke bevist noe av dette, for kravene du har satt oppfylles lett av det meste consumerutstyr med begge hendene bundet på ryggen. Ingen høyttalere har selvsagt noen sjanse på dette, high end eller ei, de lar seg tross alt ikke plassere så nøyaktig og selv de iboende tidsfeilene er jo langt større enn de som følger av plasseringsfeil på 2mm.
- Menneskelig temporal oppløsning har ingen forbindelse med den høyeste frekvensen vi kan høre...
Eh, jo, det har den. Den høyeste tidsoppløsningen vi kan identifisere er en fraksjon av den høyeste frekvensen vi kan høre. Dette handler ikke om hjernens presisjon men hvordan et signal er bygget opp. For at vi skal kunne høre en tidsforskjell på 5µs, noe man i de fleste tilfeller bare kan glemme, må man ha en veldig skarp transient som dekker hele det hørbare spekteret hele veien opp. Vi kan ikke registrere en stigetid som overgår grensen for hva vi kan høre i frekvens og amplitude. Når forskjellene i tid blir små kan de enkelt oversettes til nivå (vi kan se på stigetiden til de to eksemplene og se hvor mange dB som skiller dem), og da sier det seg selv at når forskjellene blir små nok er det ikke mange nok dB i forhold til den samlede amplituden til at vi kan høre det.
Men slike transienter finner vi i svært liten grad i musikk. Det er bare å ta en kikk på fasekarakteristikken og frekvensresponsen i toppen for en mikrofon.
Beklager, men det er ikke lett å se at dette skulle være faglig motivert.Takk for at du tok deg tid til å skrive ned alt dette Snickers. Jeg begynte å lure på om dette virkelig var seriøst når han "forklarte" oss at et piano som spilles baklengs har samme FFT men låter helt annerledes. Skulle dette være et slags bevis for at en FFT ikke er nyttig? Orket ikke se mer etter at han gjorde et stort poeng ut av frekvensspektrumet ikke er viktig men at tidsinformasjon er superviktig. Måten dette bevises på er at når man klipper bort starten og slutten av et kort bit musikkinformasjon så er det ikke så lett å identifisere instrumentet. Hallo... SELVFØLGELIG er det slik. Hva er nytt? Jeg synes det er topp at Amir laget en video som debunker denne liksomforskningen som er basert på antakelser hele veien.
Kortversjon/analogi:
Hvis du forteller en historie baklengs gir den ikke mening. Det beviser at ordene ikke betyr noe som helst, bare rekkefølgen.
Jeg vil hevde at det er å trekke en konklusjon som på ingen måte understøttes av det man faktisk har testet.
Hvis noen er interessert i emnet som handler om transienter og definisjon i musikk og tale så anbefaler jeg denne relativt lettleste artikkelen med noen interessante lytteeksempler tatt til det litt ekstreme. Artikkelen balanserer en smule bedre enn Youtuberen Kunchur sin variant:
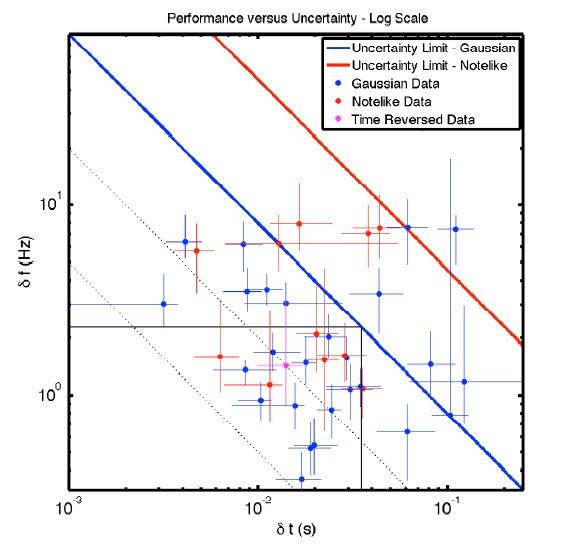
Human hearing beats the Fourier uncertainty principle
(Phys.org)—For the first time, physicists have found that humans can discriminate a sound's frequency (related to a note's pitch) and timing (whether a note comes before or after another note) more than 10 times better than the limit imposed by the Fourier uncertainty principle. Not...phys.org
Trente lyttere og bestått lyttetrening er kanskje en start :Hvem er det som kontrollerer lytteren(e) før påstander kan verifiseres?
Finnes det vitenskapelig bevis for at den subjektive lydopplevelsen KAN være lik på 2 eller flere personer i et lyttepanel?
...
https://harmanhowtolisten.blogspot.com/
Harman's "How to Listen" Listener Training Software Now Available as Beta
Well, it's been some time coming, but the listener training software Harman How to Listen is finally available for free download here . T...seanolive.blogspot.com
De enkle spørsmålene er hvor følsom lytteren er for reelle endringer i reproduksjonen av hermetikken - hovedsaklig volum, frekvensrespons, støy og forvrenging. Er lytteren god til å skille mellom reelle endringer, så er det kanskje grunn til å tro at lytteren også kan skille reelle endringer som konsekvens av bytte av ledninger, gitt at det er reelle forskjeller å finne.
Helt uten vitenskaplig bevis tror jeg det er svært lite sannsynlig at to personer vil kunne ha «lik» subjektiv opplevelse, den katten er begravd i subjektiv. Hvordan man nå enn skal kunne gå frem for å finne ut at to subjektive opplevelser ev kan være «like», det er definitivt «beyond me» som det heter på nynorsk, med eller uten fersk ørevoks.
Men før det finnes gode lyttetester som påviser at det er noe annet enn det som allerede er godt forklart ved egenskapene i apparatenes grensesnitt og ledningenes elektriske parametre, så er det lite grunnlag for «vitenskaplige fremskritt» i den retningen - det er ingen ting nytt å finne.
mvh
KJSist redigert:Snickers, du burde bli Youtuber du også Setter pris på at du deltar og bruker av din tid. Selv om man ikke altid (nesten aldri virker det som) er enig, så blir man ved å tenke over det.
Så....
Er objektivistene blitt subjektivister og motsatt? Var det ikke objektivistene som støttet seg til vitenskapen og forskningen, det målbare, det publiserte, det fagfellevurderte. Velger man dette helt bort når det ikke lengre passer med sin egen modell.
Et helt fagfelt innen psykoakustikk lurer sikkert på hvorfor deres forskning og modeller blir sett helt bort fra, selv når de blir vist til i vitenskapelige sammenhenger. Nei, jeg tror ikke de lurer så mye på det egentlig.
Det er flott at det publiserses og at kunnskapen bygges opp lag for lag innen vår lille hobby. Det er flott at Kunchur og andre publiseres i Journal of the Audio Engineering Society, i Physics News magazine og andre plasser. Det er spennende at noe av det finnes på Youtube i populær form.
Snickers burde virkelig prøve å bruke sine kunnskaper inn mot slike miljøer. Her kan man virkelig lære, her får man virkelig gjennomslag om man kommer med noe. Her får man så hatten passer også. Skal man være objektivist så har man egentlig ikke noe annet valg enn å falle inn i den vitenskapelige konsesus. Noe annet må man jobbe med å bevise, eller motbevise andre som har lagt sten til konsensus. Det det er så mye enklere å missforstå en Youtube video, eller selv å lage en Youtube video hvor man plukker fra artikkler. "At a minimum he should tell us what these cables are so that we can replicate this testing. He doesn’t even tell us what the brands are…". Joda Amir, det sto der. Selvsagt sto det der.
Jeg ser frem til neste publisering som Kunchur oppgir blir "Temporal aspects of musical sounds and their reproduction". Jeg forventer at alle relevante fag blir del av fagfellevurderingene som skal gjøres. Jeg fester lit til den vitenskapelige metoden i en jungel av andre meninger der ute. -
Laster inn…
Diskusjonstråd Se tråd i gallerivisning
-
-
Laster inn…