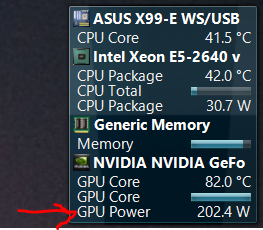
KI om det mest komplekse temaet på jord 
Valg av dimensjon på en høyttalerkabel avhenger av flere faktorer, inkludert lengden på kabelen, effekten som skal overføres, og den elektriske motstanden som er akseptabel. Her er noen retningslinjer for valg av dimensjon på en 5 meter lang høyttalerkabel:
1. **Kabeltype**: Generelt anbefales det å bruke høyttalerkabler som har god ledningsevne. Kobberkabler er det vanligste valget, da de gir minimal motstand.
2. **Kabeltykkelse (AWG)**: For en høyttalerkabel på 5 meter, er det vanligvis tilstrekkelig med en kabeltykkelse på 16 AWG (American Wire Gauge) for de fleste hjemmeanlegg.
- Hvis du planlegger å bruke kabelen til høyere effekt (for eksempel effektforsterkere), kan det være lurt å bruke en tykkere kabel, som 14 AWG eller til og med 12 AWG.
3. **Strøm og motstand**: Jo større diameter på kabelen, jo mindre motstand vil den ha, som igjen reduserer signaltap. For en 5-meter lang kabel vil forskjellen mellom 16 AWG og 14 AWG i praksis ikke være enorm, men ved høyere effektnivåer kan det være opptil 15-20 % signaltap med en tynnere kabel.
4. **Bruksområde**: Tenk på bruken. Til hjemmebruk med små eller mellomstore forsterkere er 16 AWG vanligvis tilstrekkelig. For profesjonelle oppsett, konsertlydtjenester eller kraftigere anlegg, kan du vurdere tykkere kabler.
**Oppsummering**: For en 5 meter lang høyttalerkabel er 16 AWG et godt valg for vanlige hjemmeanlegg, mens 14 AWG eller 12 AWG kan være bedre for kraftigere oppsett. Sørg også for å bruke kvalitetskabler for best mulig overføring.
Valg av dimensjon på en høyttalerkabel avhenger av flere faktorer, inkludert lengden på kabelen, effekten som skal overføres, og den elektriske motstanden som er akseptabel. Her er noen retningslinjer for valg av dimensjon på en 5 meter lang høyttalerkabel:
1. **Kabeltype**: Generelt anbefales det å bruke høyttalerkabler som har god ledningsevne. Kobberkabler er det vanligste valget, da de gir minimal motstand.
2. **Kabeltykkelse (AWG)**: For en høyttalerkabel på 5 meter, er det vanligvis tilstrekkelig med en kabeltykkelse på 16 AWG (American Wire Gauge) for de fleste hjemmeanlegg.
- Hvis du planlegger å bruke kabelen til høyere effekt (for eksempel effektforsterkere), kan det være lurt å bruke en tykkere kabel, som 14 AWG eller til og med 12 AWG.
3. **Strøm og motstand**: Jo større diameter på kabelen, jo mindre motstand vil den ha, som igjen reduserer signaltap. For en 5-meter lang kabel vil forskjellen mellom 16 AWG og 14 AWG i praksis ikke være enorm, men ved høyere effektnivåer kan det være opptil 15-20 % signaltap med en tynnere kabel.
4. **Bruksområde**: Tenk på bruken. Til hjemmebruk med små eller mellomstore forsterkere er 16 AWG vanligvis tilstrekkelig. For profesjonelle oppsett, konsertlydtjenester eller kraftigere anlegg, kan du vurdere tykkere kabler.
**Oppsummering**: For en 5 meter lang høyttalerkabel er 16 AWG et godt valg for vanlige hjemmeanlegg, mens 14 AWG eller 12 AWG kan være bedre for kraftigere oppsett. Sørg også for å bruke kvalitetskabler for best mulig overføring.
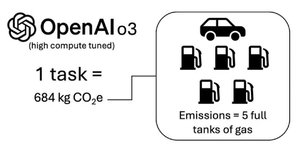




















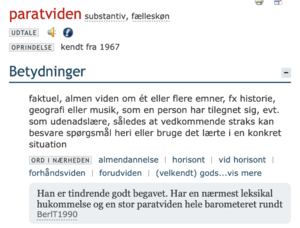
")